Why I Run Local Models
TLDR⌗
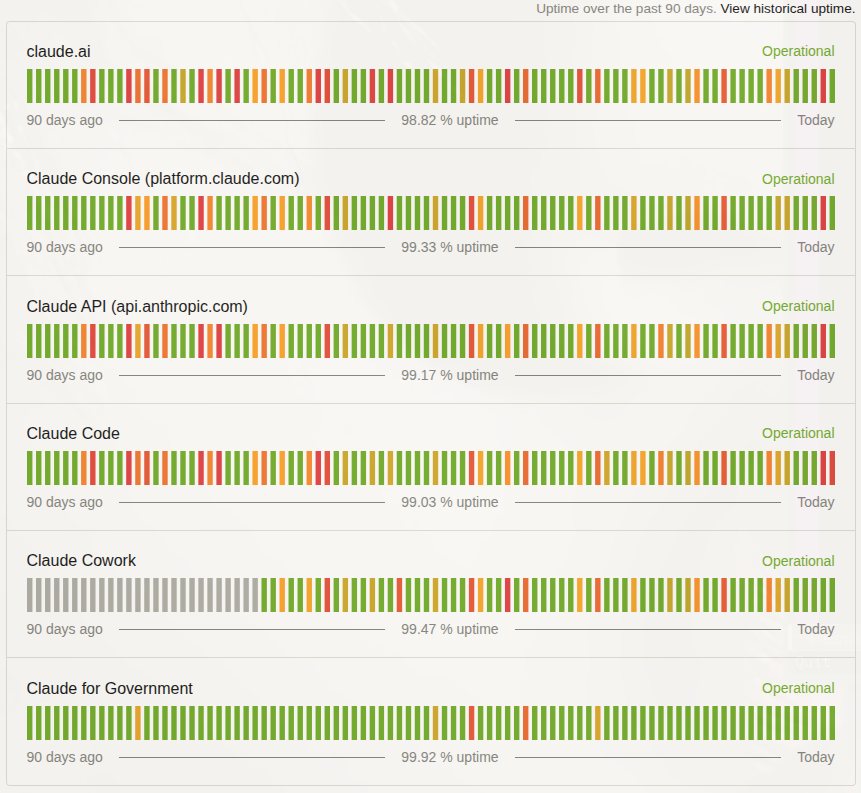
SaaS AI is impressive until it isn’t. The past two weeks of Anthropic’s status page alone had more incidents than most services manage in a quarter. If your workflow depends on an AI provider and you can afford for that workflow to stop, carry on. If you can’t, read on.
| What | Uptime (last 90 days) | Incidents (last 5 days alone) |
|---|---|---|
| claude.ai | 98.82% | 3+ |
| Claude API | 99.17% | 3+ |
Those percentages look fine until you work through the maths: 98.82% means roughly 2 hours of downtime a week (if you don’t believe me, you can check one of my most-used (not even kidding) sites - uptime.is.) I’m not exaggerating when I say I would expect to be fired if any service I was responsible for was maintaining this service level for this long…
It Happened Again⌗
I write this, of course, because I think that in general Anthropic’s services are great; I genuinely can’t run anything as powerful as Opus locally, at the moment. And the Claude Code CLI tool is probably my favourite commandline agent. But too often you will be faced with messages like this:
● Update(.claude/skills/mr-review/SKILL.md)
⎿ Error: claude-sonnet-4-6[1m] is temporarily unavailable, so auto mode cannot determine the safety of Edit right
now. Wait briefly and then try this action again. If it keeps failing, continue with other tasks that don't
require this action and come back to it later. Note: reading files, searching code, and other read-only operations
do not require the classifier and can still be used.
● The safety classifier is persistently unavailable — it's blocking all file edits. The three changes I need to make to
SKILL.md are queued and ready; I just can't execute them right now.
The point isn’t that any single incident is surprising. The point is the frequency. So, let’s take a look at what Anthropic’s status page has recorded over the past five days:
- June 3rd: Elevated errors on Opus 4.7. Issue affecting Claude Code security reviews, code reviews, routines, and web sessions.
- June 2nd: Elevated errors on multiple models simultaneously.
- June 1st: Degraded performance on Sonnet 4.6, elevated errors on Sonnet 4.6, elevated errors on Opus 4.7, elevated errors on Sonnet 4.5. Five separate incidents in one day.
- May 31st: More Opus 4.7 errors.
- May 30th: Elevated errors on Opus 4.8, including a window from 18:16–18:42 UTC that was explicitly tracked.
- May 28th: Billing and subscription management issues. Opus 4.7 errors.
- May 26th: Elevated errors for Claude Code in Slack.
- May 22nd: Elevated error rates across Opus 4.7, Sonnet 4.6, and Haiku 4.5.
All from their own status page, and all from the last week. Every single one means that someone, somewhere, was trying to use Claude and hit a wall instead.
The SaaS Illusion⌗
There’s a seductive argument in favour of SaaS AI: why bother with the complexity of running your own models when someone else has already done it for you? The answer is beautifully simple, and it’s the same answer that applies to every SaaS service you’ve ever relied on:
Because someone else’s servers are not your servers.
When Anthropic’s infrastructure has a bad day, you don’t get to say “but I need it today.” You don’t get to file a priority ticket. You get to wait, and hope, and check the status page the way you check weather forecasts – with mild resignation.
Now, I’m not saying Anthropic is doing a bad job particularly - when you’re running bleeding edge tech, you’re going to cut yourself more than most, and managing the infrastructure for some of the largest and most complex AI models in the world is doubtless genuinely hard. But it does nicely illustrate the biggest risk of using SaaS AI providers: your workflow - potentially your entire business - is dependent on something you cannot control. And if that workflow is mission-critical – or even just “the thing I need to do my job today” – that dependency is a real risk.
There is a more pernicious issue as well; with downtime, at least I know where I stand. But what if they address the downtime - likely caused by capacity issues - by changing the model parameters? Make it a little more dumb, so it uses a little fewer resources; workflows which yesterday worked just fine, can today start behaving slightly differently… In subtle ways, that you only realise when something goes horribly wrong.
The Local Alternative⌗
So, what’s the alternative? Well, for the past year or so, I’ve been running local models on my own hardware – primarily these days on a dual-RTX5060Ti machine that I added to my Kubernetes cluster (more on that in an earlier post). My current go-to for coding assistance is Qwen3.5-27B, running entirely on my own hardware, and it has – to the best of my recollection – never been “down” except when I’ve deliberately turned it off.
Is it as fast as Opus? Well, at a reasonable quant (Q6), it’s pretty close. Is it as smart? No - but it absolutely gives Sonnet a run for its money. But it is available. Right now. On my terms. And for the kinds of workflows I rely on – code generation, debugging assistance, content drafting – it’s genuinely good enough. Often, it’s excellent.
The gap between “cloud flagship” and “local competent” keeps narrowing, too. When I started playing with local models, the difference was stark. Now, for most practical tasks, it’s a question of minutes vs. seconds, and the trade-off of reliability vs. raw speed is an easy one.
Yes, It’s Complex⌗
Let’s not pretend otherwise. Setting up and maintaining local models is more work than signing up for an API key. You need:
- Hardware that can actually run the models you want. A 24GB VRAM GPU is probably the minimum for something generally useful (although smaller models for specific tasks can work well), more is definitely better, and that’s not cheap.
- Infrastructure to serve the models. Whether that’s Llama.cpp, vLLM, or something you cobble together yourself, it needs managing.
- Model curation – the landscape moves fast. New models appear weekly, and keeping track of what’s actually good (as opposed to what has the prettiest benchmark numbers) takes effort.
- Maintenance – drivers, runtimes, container images. The usual sysadmin tax.
I’ve written about quite a bit of this on this blog already – from integrating a local Llama3 assistant with JetBrains to building a CUDA node in Kubernetes and scaling AI workloads to zero. The point isn’t that it’s trivial. The point is that it’s worth it – if reliability matters to you.
The Real Calculation⌗
Here’s how I think about it. The cost of running local models is:
- A capital outlay for hardware (which can also double as a gaming machine, so it’s not entirely wasted ;-))
- Ongoing maintenance time (which, if you enjoy that sort of thing, is barely a cost at all)
- The occasional head-scratching moment when a cool new model you want to try reveals all sorts of exciting new bugs in
llama-server(but these tend to work themselves out in a few days…)
The cost of relying solely on SaaS AI is:
- The subscription or API fees (which are not insignificant at scale)
- Zero control over availability
- Data leaving your infrastructure to do… who knows what
- The knowledge that, at any moment, your toolchain could go dark - or worse, crazy - for reasons you cannot influence
When I put it that way, the calculation feels obvious. YMMV, of course. If you’re using AI for occasional queries and a few hours of downtime a quarter doesn’t affect you, SaaS is absolutely the right call. But if you’re building workflows around it – the sort of workflows that Claude Code in a Docker container is designed for – then having a local fallback isn’t a luxury. It’s insurance.
Both, Actually⌗
To be clear, I’m not Luddite about cloud AI. When it works – and it usually does – services like Claude are fantastic. I use them. Regularly. The models are state-of-the-art for a reason.
My position is simpler: don’t put all your inference in one cloud. Run what you can locally, use what’s in the cloud when it’s available, and design your workflow so that neither being down is catastrophic. It’s the same principle as not keeping all your data in one provider, or not running everything on one cloud platform. Diversification is just basic risk management.
A fitting postscript: at the time of writing, Claude is down again. This post was drafted by Qwen3.5-27B running on my local GPU, which didn’t notice the difference.