AI on-demand with Kubernetes (Part 2)

In part 1 I succeeded in setting up a CUDA-capable node on my Kubernetes cluster, and thanks to the NVIDIA GPU operator, have Kubernetes capable of scheduling suitable workloads.
In this part, I’ll take a typical AI workload - in this case, the generative image AI application ComfyUI, deploy it in Kubernetes, and then work out how to configure it to scale down to zero when I’m not using it (leaving my computer free to play Shadow of the Tomb Raider in peace,) and then to scale it back up again on-demand when I want to use Comfy.
Building and Deploying an AI app⌗
If you followed the first half of this story, you’ll know that this is pretty painless - essentially I just need to make sure that my Kubernetes deployment requests the right runtime, GPU resources, and away we go. For completeness though, I’ll include all the details here.
Putting ComfyUI in a Docker container⌗
Firstly, we’ll need a Docker image capable of running Comfy. That basically means a container with a few gigabytes of Python libraries installed, and the ComfyUI application itself.
As a base image, I’ll use one of NVIDIA’s base-images that includes all the
CUDA/GPU drivers already baked into it; the key thing to note here is that
you’ll want an image that matches the version of the CUDA drivers installed
on your host nodes. You can check that with nvidia-smi:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 On | Off |
| 0% 36C P8 30W / 450W | 445MiB / 24564MiB | 11% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
I have CUDA version 12.2 on my host, so I’ll use a corresponding image: nvidia/cuda:12.2.0-base-ubuntu22.04.
The Dockerfile that I created to then install ComfyUI is pretty unremarkable. Note that I do also include some other custom nodes that I’ve found useful at one time or another:
FROM nvidia/cuda:12.2.0-base-ubuntu22.04
RUN apt-get update
# Satisfy tzdata whingeing from APT
ARG DEBIAN_FRONTEND=noninteractive
ENV TZ=Etc/UTC
RUN apt-get install -y tzdata
# Install a current version of Python
RUN apt-get -y install software-properties-common
RUN add-apt-repository -y ppa:deadsnakes/ppa
RUN apt-get update
RUN apt-get install -y python3.11
RUN apt-get install -y python3.11-dev
# And make sure it's the one we want
RUN update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.11 10
RUN update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.10 1
RUN update-alternatives --auto python3
# PIP
RUN apt-get install -y python3-pip
RUN pip3 install --upgrade pip
# GIT
RUN apt-get install -y git
# Now, start installing ComfyUI
WORKDIR /usr/local
RUN git clone https://github.com/comfyanonymous/ComfyUI.git
# Some custom nodes that I find useful
WORKDIR /usr/local/ComfyUI/custom_nodes
RUN git clone https://github.com/Extraltodeus/ComfyUI-AutomaticCFG
RUN git clone https://github.com/Clybius/ComfyUI-Extra-samplers
RUN git clone https://github.com/flowtyone/ComfyUI-Flowty-LDSR.git
RUN git clone https://github.com/ltdrdata/ComfyUI-Manager
RUN git clone https://github.com/Suzie1/ComfyUI_Comfyroll_CustomNodes.git
RUN git clone https://github.com/city96/ComfyUI_ExtraModels
RUN git clone https://github.com/ssitu/ComfyUI_UltimateSDUpscale --recursive
# Install all the package dependencies
WORKDIR /usr/local/ComfyUI
RUN pip3 install --default-timeout=1000 --no-cache-dir torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu122
RUN find . -name requirements.txt -exec pip3 --no-input install --default-timeout=1000 --no-cache-dir -r {} \;
COPY comfyui.sh /usr/local/bin/comfyui
ENTRYPOINT [ "/usr/local/bin/comfyui" ]
For completeness, the comfyui.sh entrypoint script just looks like this:
#!/bin/sh
cd /usr/local/ComfyUI
/usr/bin/python3 main.py $*
The result of this is not a small Docker image (in fact, it’s around 6GB…), but I’m using a private registry and not uploading over the Internet, so I’ve not really made any effort to optimise that. It works well enough for our purposes.
It might be worth noting, this includes no model data/tensorfiles at this point. I’ll deal with that in the Kubernetes deployment. At the most basic, we just need a Pod to contain our ComfyUI docker image, and a LoadBalancer to give me access to it:
---
apiVersion: v1
kind: Service
metadata:
name: comfyui
labels:
app: comfyui
spec:
type: LoadBalancer
ports:
- port: 80
name: http
targetPort: 8188
selector:
app: comfyui
---
apiVersion: v1
kind: Pod
metadata:
name: comfyui
labels:
app: comfyui
spec:
runtimeClassName: nvidia
tolerations:
- key: restriction
operator: "Equal"
value: "CUDAonly"
effect: "NoSchedule"
containers:
- name: comfyui
image: registry.svc.snowgoons.ro/snowgoons/comfyui:2024-07-02
args: [ "--listen", "0.0.0.0" ]
imagePullPolicy: Always
resources:
limits:
nvidia.com/gpu: 1
ports:
- containerPort: 8188
name: comfyui
volumeMounts:
- mountPath: /usr/local/ComfyUI/models
name: model-folder
volumes:
- name: model-folder
hostPath:
path: /usr/local/ai/models/comfyui
As before, we include the runtimeClass and nvidia.com/gpu attributes that
tell it we need GPU access, as well as a toleration to let it run on my CUDA
capable machine. One kubectl apply later, and we have ComfyUI running in
Kubernetes.
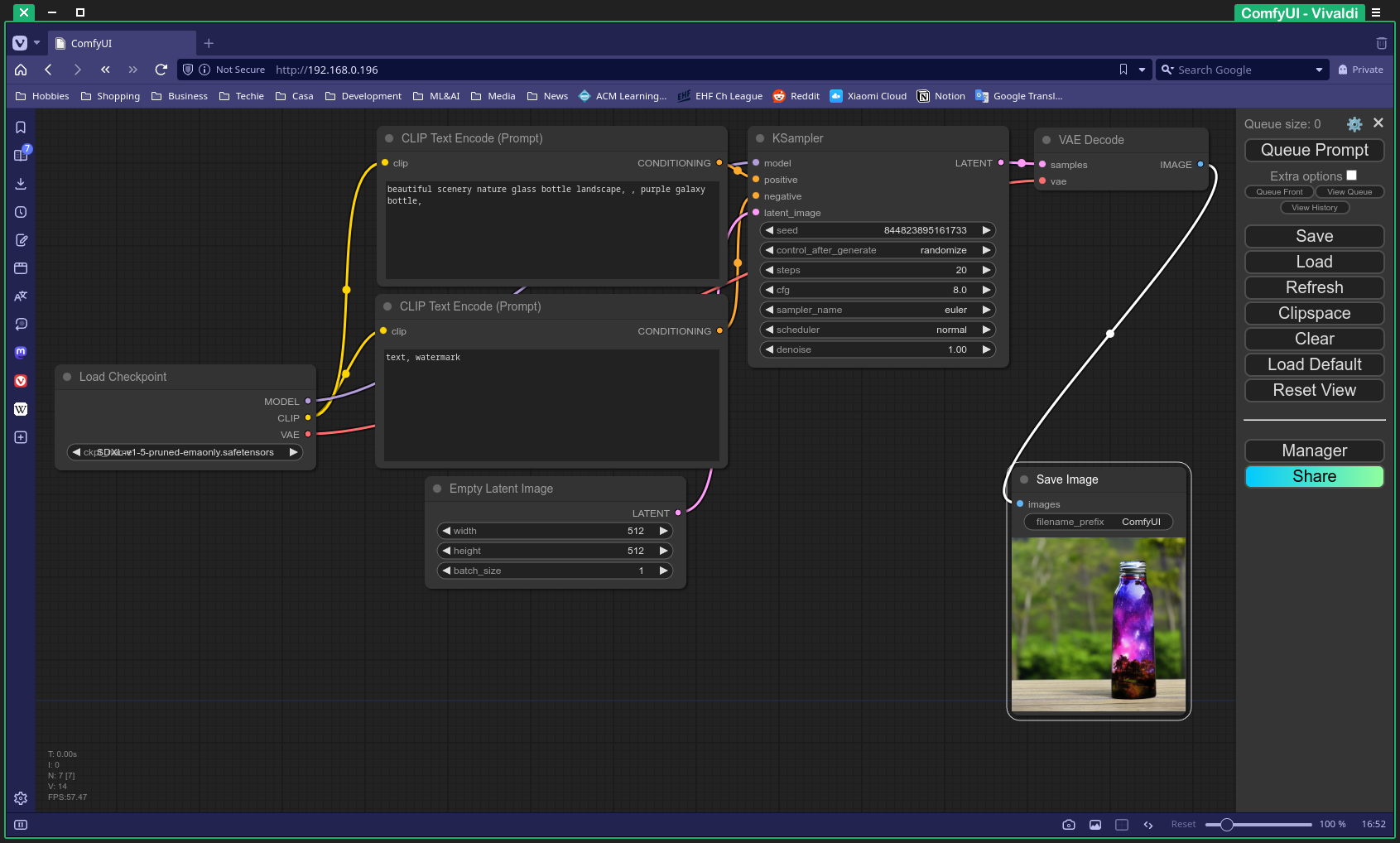
Scale to Zero⌗
So, now for the fun part. I want my application to be available whenever I want it - I want to just point my browser at the URL, and have it work immediately (or at least, as close to immediately as possible.) Equally, when I walk away and decide to do something else, I’d like those resources to be cleaned up for me so I can use them for more important things. Like Lara Croft.
Typically, scaling up and down would be handled using a HorizontalPodAutoscaler -
with just one small problem: the standard HPA can’t scale down to zero.
The canonical solution to this is to use something like KNative, and it’s a solution that works extremely well for event-based workloads; KNative can monitor an event bus, and when there is nothing in the queue it will scale your workload down to zero, and when events start appearing in the queue it scales them up again to handle. It works very well in practice as well as theory, and in my day job we have production KNative workloads managed exactly like this.
Unfortunately though, in this case my services are not event based, they are web based HTTP applications - and HTTP is very much connection and request oriented, not event based. How to square the circle?
The obvious answer is to develop some kind of HTTP proxy that could sit in front of our applications and generate suitable events; when a request comes in, it could effectively ‘put the request on hold’ if there are no backends available to process them, and generate a suitable event to cause the service to scale up and then handle the request.
This seems a promising approach, but before I set about developing such a thing, I wanted to see if there was something else out there that could already handle it.
Enter KEDA⌗
Well, what would you know, apparently there is - KEDA. Like KNative, KEDA is fundamentally an event-driven autoscaling tool, but it seems there is a plugin - KEDA HTTP designed to do exactly what I need. So, let’s see if it works…
Installing KEDA & KEDA HTTP⌗
I’ll install the KEDA operator and associated components in the keda-scaler
namespace from the provided Helm chart, like so:
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install --create-namespace -n keda-scaler keda kedacore/keda
OK, so far so good, now let’s try to install the HTTP add-on:
helm install --create-namespace -n keda-scaler http-add-on kedacore/keda-add-ons-http
A quick look at the pods running in our keda-scaler namespace suggests things
are going OK so far:
> kubectl get pods
NAME READY STATUS RESTARTS AGE
keda-add-ons-http-controller-manager-7b4b8bdfc7-ddv9w 2/2 Running 0 41s
keda-add-ons-http-external-scaler-54d5c986fb-cp46g 1/1 Running 0 41s
keda-add-ons-http-external-scaler-54d5c986fb-cqmkd 1/1 Running 0 41s
keda-add-ons-http-external-scaler-54d5c986fb-plb7t 1/1 Running 0 41s
keda-add-ons-http-interceptor-6cd8f677bb-tjxpp 1/1 Running 0 24s
keda-add-ons-http-interceptor-6cd8f677bb-zrg9v 1/1 Running 0 24s
keda-add-ons-http-interceptor-6cd8f677bb-zwkqp 1/1 Running 0 41s
keda-admission-webhooks-554fc8d77f-mx9d2 1/1 Running 0 5m39s
keda-operator-dd878ddf6-27t7v 1/1 Running 1 (5m20s ago) 5m39s
keda-operator-metrics-apiserver-968bc7cd4-k4gkf 1/1 Running 0 5m39s
OK! So let’s see if we can get it working. We need to create an HTTPScaledObject in our ComfyUI deployment’s namespace.
Configuring KEDA HTTPScaledObject⌗
Note that the specification of the HTTPScaledObject appears to have changed somewhat since the announcement linked above; the current version, which I will use as the basis for my efforts, is 0.8.0, documented here.
Firstly, and unsurprisingly, the KEDA autoscaler doesn’t work directly on Pods, but rather on Deployments. So I need to update my simple ComfyUI accordingly; let’s do that now:
apiVersion: apps/v1
kind: Deployment
metadata:
name: comfyui
labels:
app: comfyui
spec:
replicas: 1
selector:
matchLabels:
app: comfyui
template:
metadata:
labels:
app: comfyui
spec:
runtimeClassName: nvidia
tolerations:
- key: restriction
operator: "Equal"
value: "CUDAonly"
effect: "NoSchedule"
containers:
- name: comfyui
image: registry.svc.snowgoons.ro/snowgoons/comfyui:2024-07-02
args: [ "--listen", "0.0.0.0" ]
imagePullPolicy: Always
resources:
limits:
nvidia.com/gpu: 1
ports:
- containerPort: 8188
name: comfyui
volumeMounts:
- mountPath: /usr/local/ComfyUI/models
name: model-folder
volumes:
- name: model-folder
hostPath:
path: /usr/local/ai/models/comfyui
Now we need to craft a scalar configuration:
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: comfyui
spec:
scaleTargetRef:
name: comfyui
kind: Deployment
apiVersion: apps/v1
service: comfyui
port: 80
replicas:
min: 0
max: 1
scaledownPeriod: 60
scalingMetric:
requestRate:
window: 1m
targetValue: 1
granularity: 1s
What are the important things to note here?
Firstly, the scaleTargetRef identifies two things: the Deployment we plan to
scale, and also the Service which we should be intercepting. The port
number specified is the port of the service, not the backend port exposed
by the backend deployment/pods.
Secondly, we are specifying zero as our minimum number of replicas. And only 1 as the maximum. So essentially our ComfyUI will either be ‘on’ or ‘off’.
What will determine whether or not our deployment is scaled up are the metrics that KEDA tracks - we’re going to use HTTP request rate here. In this case, I say that if there is at least 1 request per minute, keep the service alive - otherwise, you can scale it down to zero.
OK, so let’s deploy:
> kubectl apply -f scaler.yaml
httpscaledobject.http.keda.sh/comfyui created
That seemed easy. I wonder what happened?
> kubectl get pods
No resources found in ai-tests namespace.
What happened to my comfyui pod? I’m hoping this means it scaled it down
to zero… Let’s have a look at the deployment:
Name: comfyui
Namespace: ai-tests
CreationTimestamp: Wed, 03 Jul 2024 18:11:54 +0300
Labels: app=comfyui
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=comfyui
Replicas: 0 desired | 0 updated | 0 total | 0 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=comfyui
Containers:
comfyui:
Image: registry.svc.snowgoons.ro/snowgoons/comfyui:2024-07-02
Port: 8188/TCP
Host Port: 0/TCP
Args:
--listen
0.0.0.0
Limits:
nvidia.com/gpu: 1
Environment: <none>
Mounts:
/usr/local/ComfyUI/models from model-folder (rw)
Volumes:
model-folder:
Type: HostPath (bare host directory volume)
Path: /usr/local/ai/models/comfyui
HostPathType:
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: comfyui-db75858f6 (0/0 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 8m51s deployment-controller Scaled up replica set comfyui-db75858f6 to 1
Normal ScalingReplicaSet 5m51s deployment-controller Scaled down replica set comfyui-db75858f6 to 0 from 1
Look at that! That last log entry is the giveaway: It worked!
OK, so now if I point my browser at my service as before, it should spin up a new instance right?
Wrong. It doesn’t work. Why not? And you may also have noticed some errors
like there isn't any valid interceptor endpoint popping up in your
keda-add-ons-http-external-scaler pods as well, if you’re the type that
actually checks the logs. What’s that all about?
Well, it seems that in fact to intercept our requests, we need to go through
the keda-gttp-add-on-interceptor-proxy service that was deployed as part
of the KEDA HTTP addon Helm chart.
The easiest way to do this is probably to set up an Ingress that will point to it. Let’s do that…
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: comfyui-ingress
namespace: keda-scaler
spec:
ingressClassName: nginx
rules:
- host: "comfyui.svc.snowgoons.ro"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: keda-add-ons-http-interceptor-proxy
port:
number: 8080
Note that the Ingress needs to be specified in the namespace of the keda-scaler, not our target applications namespace, so it can route to the proxy.
Now that we’ve done that, it’s clear that the KEDA proxy also needs some way to
work out which backend it will route to. So we need to specify some rules,
either path or host based, which tell it. We do that in the HTTPScaledObject
specification, by adding hosts: or pathPrefixes: entries; let’s update it:
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: comfyui
spec:
hosts:
- comfyui.svc.snowgoons.ro
pathPrefixes:
- /
scaleTargetRef:
name: comfyui
kind: Deployment
apiVersion: apps/v1
service: comfyui
port: 80
replicas:
min: 0
max: 1
scaledownPeriod: 60
scalingMetric:
requestRate:
window: 1m
targetValue: 1
granularity: 1s
You know what to do. kubectl apply, and then let’s point our browser at
our ingress address, and see what happens…
Which is: it works! After a brief pause, we got our ComfyUI back!
Let’s see the pods, to make sure we’re not imagining it:
> kgp
NAME READY STATUS RESTARTS AGE
comfyui-db75858f6-sk9g2 1/1 Running 0 6s
Oh my! And kubectl describe deployment comfyui?
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 56m deployment-controller Scaled up replica set comfyui-db75858f6 to 1
Normal ScalingReplicaSet 53m deployment-controller Scaled down replica set comfyui-db75858f6 to 0 from 1
Normal ScalingReplicaSet 2m2s deployment-controller Scaled up replica set comfyui-db75858f6 to 1 from 0
⚠️ You may be expecting a choir of angels, at this point.
But not quite. Things are not entirely perfect; because, it turns out, the KEDA HTTP addon does not support WebSockets connections, and, well that’s a problem for ComfyUI.
So, for basic, non-websockets HTTP apps, we’re basically there. For my intended use-case, which isn’t ComfyUI but rather LLM chatbot services, this is actually good enough.
And for the WebSockets case? Well, actually there is hope on that front as well; there is an open pull-request which fixes the problem in Keda: https://github.com/kedacore/http-add-on/pull/835…
Postscript: Working around the KEDA WebSockets problem⌗
Arrgh. It’s 8.30 in the evening, and I really should be making something to eat… But I just can’t leave it there. It’s irritating to be 95% of the way there, but not quite…
BUT; I thought of a workaround. It’s pretty unusual for a website to use lots of WebSocket connections, right? Usually there will be one, maybe two, and the rest of the content on the page will be delivered by boring old HTTP. What if we could route the plain-ol’-HTTP connections through KEDA, but divert the WebSocket ones so they go directly to the backend - maybe that could fix it?
Let’s try. Using the inspector in my browser tells me that the WS URL that
ComfyUI is trying to access is /ws. We should be able to make an
exception for that in our Ingress config so that skips KEDA and goes direct
to the service:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: comfyui-ingress
namespace: keda-scaler
spec:
ingressClassName: nginx
rules:
- host: "comfyui.svc.snowgoons.ro"
http:
paths:
- pathType: Exact
path: "/ws"
backend:
service:
name: comfyui-bypass-interceptor-proxy
port:
number: 8080
- pathType: Prefix
path: "/"
backend:
service:
name: keda-add-ons-http-interceptor-proxy
port:
number: 8080
---
apiVersion: v1
kind: Service
metadata:
name: comfyui-bypass-interceptor-proxy
namespace: keda-scaler
spec:
type: ExternalName
externalName: comfyui.ai-tests.svc.cluster.local
ports:
- port: 8080
targetPort: 80
Note, one important thing; the Ingress expects all its backends to live in
the same namespace as the Ingress declaration - in our case, that’s the
keda-scaler namespace, not the namespace I deployed Comfy in (ai-tests). So
we need an extra Service object of type ExternalName which will allow the
Ingress to “cross namespaces”.
Apply the changes, cross fingers, try to hit our service’s URL, and…

Note, of course, that if you use this workaround, any requests that go direct to the origin and bypass the interceptor will not be counted when KEDA makes its decision to scale up or down.