Local Llama3 Assistant in JetBrains

This falls under the category of “writing some notes here so I don’t forget what I did in the future”, but it may be useful for others, so here it is.
I’ve recently been playing with JetBrains AI service, and very nice it is too. It’s a huge productivity enhancer, and if nothing else it makes my Commit messages much better. But it has one flaw I don’t like - it depends on various cloud-based AI services, and while I actually think JetBrains’ AI Terms of Service are excellent, and a model for others to follow - well, I have trust issues. I’d rather my AI assistant ran locally on my machine (with the added bonus that then I can play about with finetuning my own models.)
So, I set about running a model locally, and finding a decent plugin to integrate it with JetBrains. I started with Meta’s Llama3 model, running on my Ubuntu Linux workstation, with Nvidia graphics card.
Running Llama3 Locally⌗
The easiest way to run Llama3 is using Llama.cpp. As well as providing a commandline application for model inference, it includes a simple webserver component that exposes an OpenAI compatible API. This is what our IDE plugin will use to communicate with the model.
Preparing the ground - dependencies⌗
To build Llama.cpp doesn’re require anything particularly special. BUT, to
build it with CUDA support, so we can offload the model to the GPU (something
I definitely want), it will need the Nvidia CUDA toolkit.
I already had a slightly older version of the CUDA toolkit installed from previous experiments, but I wanted to make sure I was using the latest release direct from Nvidia (the Ubuntu standard package repo is currently delivering 11.5.1, while the latest is 12.5).
First, I removed the already installed version:
sudo apt-get remove nvidia-cuda-toolkit
sudo apt-get autoremove
Then, follow the instructions at the Nvidia CUDA Downloads page:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.5.0/local_installers/cuda-repo-ubuntu2204-12-5-local_12.5.0-555.42.02-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-5-local_12.5.0-555.42.02-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-5-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-5
For whatever reason, the install didn’t put nvcc in my path or modify
my LD_LIBRARY_PATH correctly - probably because I am perverse and use tcsh
as my shell instead of bash like the rest of the world. So I needed to add
the following to my .tcshrc:
setenv CUDA_HOME /usr/local/cuda
setenv PATH ${PATH}:${CUDA_HOME}/bin
if ( ! $?LD_LIBRARY_PATH ) then
setenv LD_LIBRARY_PATH /usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64
else
setenv LD_LIBRARY_PATH ${LD_LIBRARY_PATH}:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64
endif
rehash
Building Llama.cpp⌗
This part is incredibly easy and worked out of the box. Just checkout the GIT repo, and
cd llama.cpp
make LLAMA_CUBLAS=1
make server
This will build with CUDA enabled (using the Nvidia CUDA toolkit) and build the webserver.
Downloading model weights and running the server⌗
The original weights are on Huggingface, but you will want quantized weights converted to GGUF format, such as MaziyarPanahi/Meta-Llama-3-8B-Instruct-GGUF
Once you have the weights somewhere, spinning up the server is as simple as:
llama.cpp/server --port 11434 \
-m /path/to/Meta-Llama-3-8B-Instruct-Q4_K_M.gguf \
--n-gpu-layers 99
Integrating with JetBrains IDEA IDEs⌗
There are a few plugins in the JetBrains marketplace for integrating with AI assistants; most of them are tied to a particular cloud service provider.
The one I have tried that I like best is CodeGPT - it works well with our local AI server, is nicely configurable, and offers my favourite feature (commit message generation :-).)
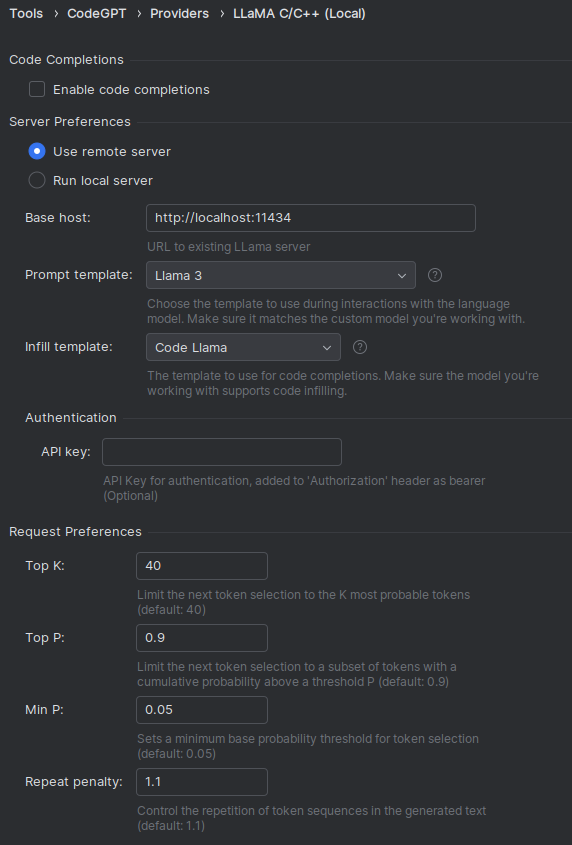
Install the plugin from the marketplace, then configure the plugin to use
the Llama C/C++ (Local) provider, pointing at your local server, as follows:
Playing with the AI’s prompt⌗
One of the nice things about CodeGPT is that it lets you play around with the AI’s system prompt, so you can change its guidance on how to respond to queries and so on. Have fun with this, but for reference here is the default prompt (just in case you screw up and want to go back to it):
You are an AI programming assistant.
Follow the user's requirements carefully & to the letter.
Your responses should be informative and logical.
You should always adhere to technical information.
If the user asks for code or technical questions, you must provide code suggestions and adhere to technical information.
If the question is related to a developer, you must respond with content related to a developer.
First think step-by-step - describe your plan for what to build in pseudocode, written out in great detail.
Then output the code in a single code block.
Minimize any other prose.
Keep your answers short and impersonal.
Use Markdown formatting in your answers.
Make sure to include the programming language name at the start of the Markdown code blocks.
Avoid wrapping the whole response in triple backticks.
The user works in an IDE built by JetBrains which has a concept for editors with open files, integrated unit test support, and output pane that shows the output of running the code as well as an integrated terminal.
You can only give one reply for each conversation turn.