Inference in the Cloud with Modal
I’ve been exploring the world of Machine Learning, lately. To do this, I have a “reasonable” graphics card (an Nvidia RTX3060 with 12gb VRAM) which is good enough to at least run inference on generative image models like Stable Diffusion locally - but for contemporary Large Language Models, or multimodal models, this little machine just doesn’t cut it for inference let alone training.
So, there’s an obvious solution, right? Cloud…
The Problem with Cloud⌗
Now, I have used AWS and Google Cloud Platform accounts for a long time, professionally and occasionally personally. Little bits of AWS go into running snowgoons.ro - DNS serving, a gateway for my Gemini server and so on. And in GCP, I have a small autoscaling managed Kubernetes cluster (GKE) that I use for playing with workloads that are too big for my local Kubernetes cluster1. But all these traditional (can we say that now?) cloud service providers share the problem that they - or rather, their costs - scale down incredibly badly.
TO give a recent example; I decided that rather than do whatever fiddling Google were imploring me to do to upgrade to the latest version of Google Analytics, I should instead take the chance to get rid of Google Analytics entirely (whatever my opinions on Google, having the GA tag on my site means asking my readers to trust Google with their data, and I’m not really comfortable with that.) But I’d still like some basic analytics so I can see if anyone is actually reading this stuff, so I needed a self-hosted replacement.
So, I found Matomo, cobbled together a suitable Helm chart, and deployed it in my GKE cloud environment to see how it works. And the answer is - pretty nicely! There was only one problem…
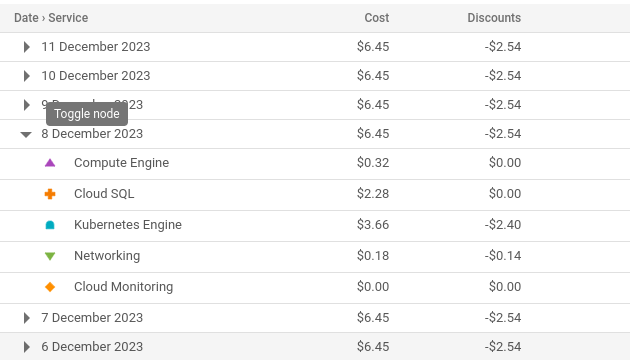
Even with the lowest-spec hardware for the database, and the smallest Kubernetes install one can muster, and vertical pod autoscaling configured to deploy the absolute minimum of resources, that thing is going to cost me nearly €200 a month, which is clearly crazy. I need to scale smaller…
Fortunately for my wallet, I worked out that for less than a month of hosting in Google Cloud, I could buy a new N100 NUC based mini-PC to add to my home Kubernetes cluster with plenty of horsepower for running the PostgreSQL database and application servers for all the analytics a tiny site like this needs. Problem solved! For this…
The problem with Inference⌗
So for simple compute workloads like that, the solution to cloud platforms not scaling down far enough is simple - just buy some cheap resources and host on-prem. But when it comes to the kind of hardware required to run some of the models I’ve been playing with recently (more on one of them in a later article), “cheap” is not available. I was curious enough to find out how much an Nvidia Ampere A100 card might set me back, and came to the conclusion I was looking at north of €20,000 if I could find someone to sell me one. And that’s without the upgraded power supply and electricity bill to go with it…
Surely there’s a better way?
Solutions!⌗
Well yes, yes there is; and it’s not Google Cloud - a month of provisioning a machine with an 80gig A100 there will set you back around €4,000, and while you can cut that down with automatic provisioning/teardown, that’s a load of effort I’d rather not put into for self-directed learning and experimentation. The real solution here is serverless - a provider that can handle all the provisioning/teardown of resources for me entirely automatically and just bill me for the actual cycles my workload uses.
Fortunately, a few such providers have popped up, and the one which I decided to try out is Modal - and I am here to tell you just how ridiculously easy it is to get set up with deploying some of your code to a high-performance cloud provider that only bills you for the actual seconds (or bytes) of compute (and memory) that you use:
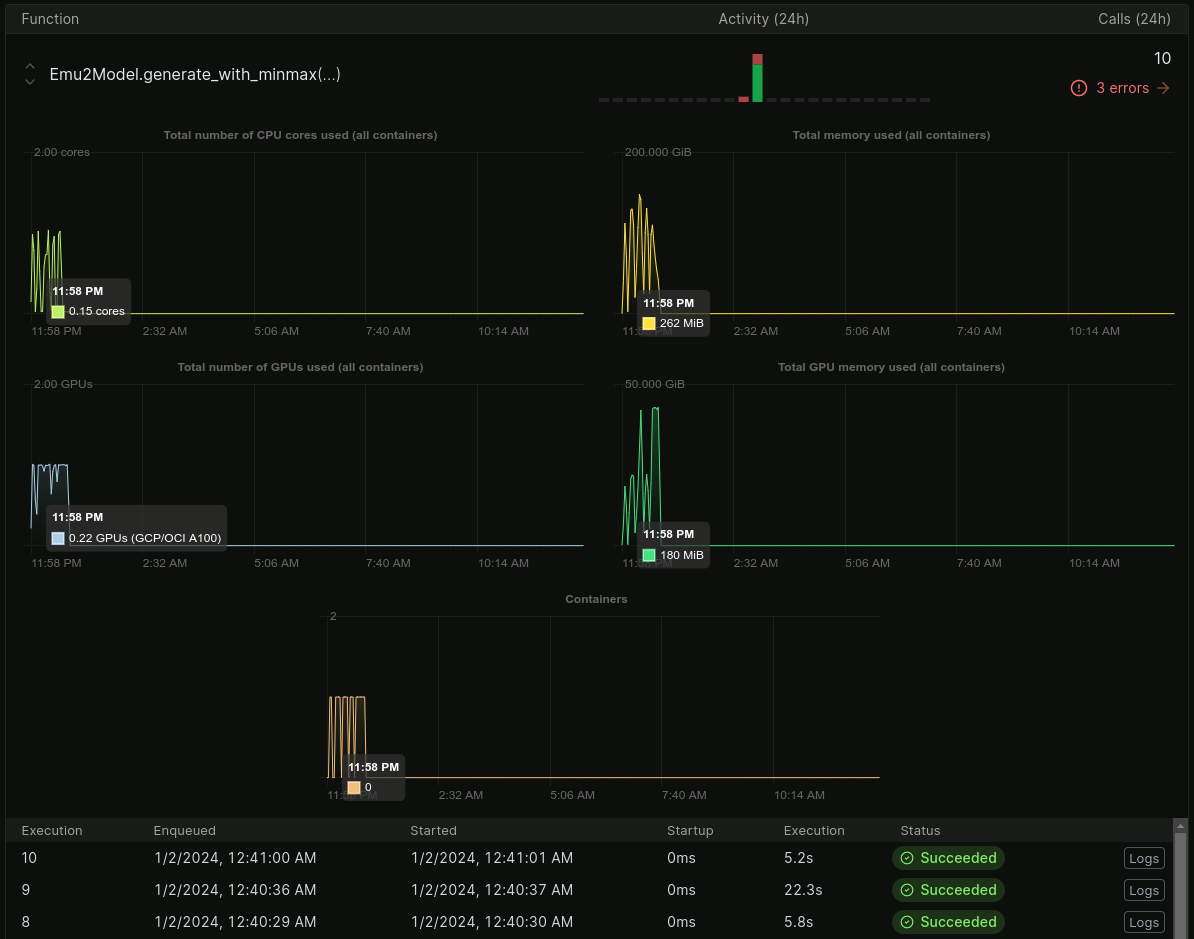
So how do you do it?⌗
The easiest thing to do here is just cut to the chase and show you the code. There’s nothing novel here - it’s mostly Modal’s own tutorial code adapted for one of the models I’ve been playing with. But it was so ridiculously simple, I felt I really had to share. So, without further ado, this is what it looks like to write a Python script where your local code executes on your machine, but some key functions execute remotely in Modal’s cloud…
Preamble⌗
We have some standard imports needed for the model I intend to run, and define some constants for the model I intend to download - this is mostly non-Modal specific.
from dataclasses import dataclass
from PIL import Image
import torch
from modal import Image as DockerImage, Secret, Stub, gpu, method
GPU_CONFIG = gpu.A100(memory=80, count=1)
MODEL_ID = "BAAI/Emu2-Chat"
REVISION = "2c69671baa7fc06525e56fc8bedfc8ffa20baf06"
There is another key declaration here of course - GPU_CONFIG. This is
going to be used later when we declare our code, and will tell Modal what
kind of hardware we want to run on. Here I’m going to ask for an 80Gig A100.
Building the Container⌗
Your Modal code will run in a Docker container on their servers; we need to give it a base image to instantiate. Ideally, in this base image we can do things like downloading our ML model from Huggingface, so all the weights are already in the image when it is instantiated - this is going to save us time (and money!) if we do that every time the container spins up.
To do this, I use the Huggingface Text Generation Inference (TGI)
base Docker image, which gives us a nice tool we can use to download the
weights. We define a helper function download_model that will be
executed as part of the container image build process (that’s the call to
.run_function).
def download_model():
"""
Download the weights for a specific model revision.
:return: None
"""
import subprocess
subprocess.run(["text-generation-server",
"download-weights",
MODEL_ID,
"--revision",
REVISION,
],
check=True)
tgi_image = (
DockerImage.from_registry("ghcr.io/huggingface/text-generation-inference:1.3.4-rocm")
.dockerfile_commands("ENTRYPOINT []")
.run_function(download_model, secret=Secret.from_name("timwa-huggingface"))
.pip_install_from_requirements("./requirements.txt")
.env({"PYTORCH_CUDA_ALLOC_CONF": "garbage_collection_threshold:0.6,max_split_size_mb:128"})
)
We also do some other bits-and-bobs here, like installing our other Python dependencies, and also passing in a secret in the environment when we run the download function which will allow it to access gated models using my credentials.
Defining my code to execute in the cloud⌗
And now, this is the really embarrasingly simple bit. All we need to do here is get hold of a “stub”, and give it a name which will later be used by our client code to look up the service. Then we declare a class which will encapsulate the code I want to run on the remote server; we annotate it with some metadata telling Modal things like the server hardware we want, and how long to keep the container around before it is spun down.
The code in the __init__ method will execute when the container spins up -
it is your ‘cold start’ penalty essentially. The spinning up/tearing down
takes place entirely automatically, but you can tweak the behaviour with
the @stub.cls class attributes (and others like keep_warm, if it’s important to have
instant response time you might want to use this to make sure there is always
at least one container ready and waiting for requests.)
Methods you want to call remotely should be tagged with the @method attribute,
to allow for the clientside RPC stub to be created. And, well, that’s literally
it:
stub = Stub("my-remote-code")
@stub.cls(
secret=Secret.from_name("timwa-huggingface"),
gpu=GPU_CONFIG,
allow_concurrent_inputs=2,
container_idle_timeout=60 * 10,
timeout=60 * 60,
image=tgi_image,
)
class MyModel:
def __init__(self):
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, revision=REVISION)
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, revision=REVISION,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
).to("cuda").eval()
self.tokenizer = tokenizer
self.model = model
@method()
async def generate(self, prompts: [str], images: [Image], params: GeneratorParams = GeneratorParams()):
inputs = self.model.build_input_ids(text=prompts,
tokenizer=self.tokenizer,
image=images)
with torch.no_grad():
outputs = self.model.generate(input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
image=inputs["image"].to(torch.bfloat16),
max_new_tokens=params.max_new_tokens,
length_penalty=params.length_penalty,
top_p=params.top_p,
top_k=params.top_k,how_to_access_bios_in_case_anyone_needs_to_know
temperature=params.temperature,
do_sample=params.do_sample,
min_len=params.min_len,
num_beams=params.num_beams)
result = self.tokenizer.batch_decode(outputs, skip_special_tokens=True)
return result
That’s it?⌗
The really is it. Well, OK, you will want to type modal deploy myfile.py
to deploy it… But essentially that’s all you need to do.
But the code to then call your remote function must be really complicated, right?
Nope…
import modal
generate = modal.Function.lookup("my-remote-code", "MyModel.generate")
response = generate.remote(method, parameters, go, here)
Seriously, it is that easy2. Go try it… In another post I’m going to write about how this has helped me to us a new model to really improve the automation of image gallery captions on snowgoons.ro in future…
-
https://snowgoons.ro/posts/2020-05-11-snowgoonsplatform/ - damn, is that really nearly 4 years old? The hardware has changed a little, but not too much… ↩︎
-
OKOK, of course there are some complications. I’ve had a few tearing-hair-out moments related to serialising complex data structures (it uses
cloudpickleunder the bonnet) and namespacing, but that’s as much down to my ignorance of Python (I only started learning it a few weeks ago) as anything else. ↩︎