Using multi-modal AI for better image captions

Using multi-modal AI for better image captions⌗
Over the last few weeks, I’ve been playing around with various generative AI models - StableDiffusion for image generation, RAM for image recognition and tagging, and a variety of Large Language Models for text generation.
Amongs other things, my chosen playground has been “automatically generating captions for my photographs”; I have long enjoyed photography, but one of the things I’m very bad at is tagging and adding titles and captions (the enjoyment for me is in the photograph and the process, not in the filing afterwards,) which seems like an ideal case to use generative AI “for good” (as opposed to evil.)
So you opened a ChatGPT account?⌗
Obviously, the easiest way to do this would just be to open an account with ChatGPT (or one of the myriad other cloud services that have popped into existence over the last few months.) But, as a general rule I don’t like anything that is too easy… And I also have more pragmatic objections to that approach.
The problems with public Generative AI models⌗
Firstly, there is a simple matter of principle at play here; I’m not free labour to help someone else train their model.
Secondly, there is a genuine motivation behind the ’too easy’ sentiment; the reason I’m doing this is to try and learn, and I don’t feel like I’m learning much about the capability of generative AI models by just using someone else’s - at best, I’m learning what OpenAI is capable of, but I’m interested in a more general understanding, and also of getting my hands dirty with Python and Torch and the rest of it…
My third reason is the most important, though; I need to understand what, if any, applications this might have commercially, in my day job. And there is a real issue with using cloud models for this. Fundamentally, while generative AI is not (necessarily) deterministic, it does at least need to be vaguely predictable to have a commercial use. I cannot deploy a service built on ChatGPT that works perfectly today, but may suddenly start behaving differently tomorrow for reasons outside my control - either because ChatGPT deliberately did something (changed to a newer version of the model, or changed the inference parameters to try and cut costs,) or because the model itself has evolved based on all the other data being fed into it by other customers. This is not even just a theoretical concern - already, within the short life of these services, changes in performance are being observed and studied; this cannot be a basis for a commercial service. No; to be able to build real-world solutions using this technology means being able to run your own models, with at least vaguely predictable results and clear accountability for who needs to fix it when it goes wrong.
So, my approach with learning how to do this has been to restrict myself to only models which I can run myself.
The experiment so far…⌗
I’ve tried a few approaches so far. To try and make the experiment vaguely fair, I’ve been using the same set of images (some photographs taken in Bucharest’s Herastrau Park last Autumn,) and then applied my AI tools to generate the captions and titles for each of the images.
The first image in the gallery looks like this:
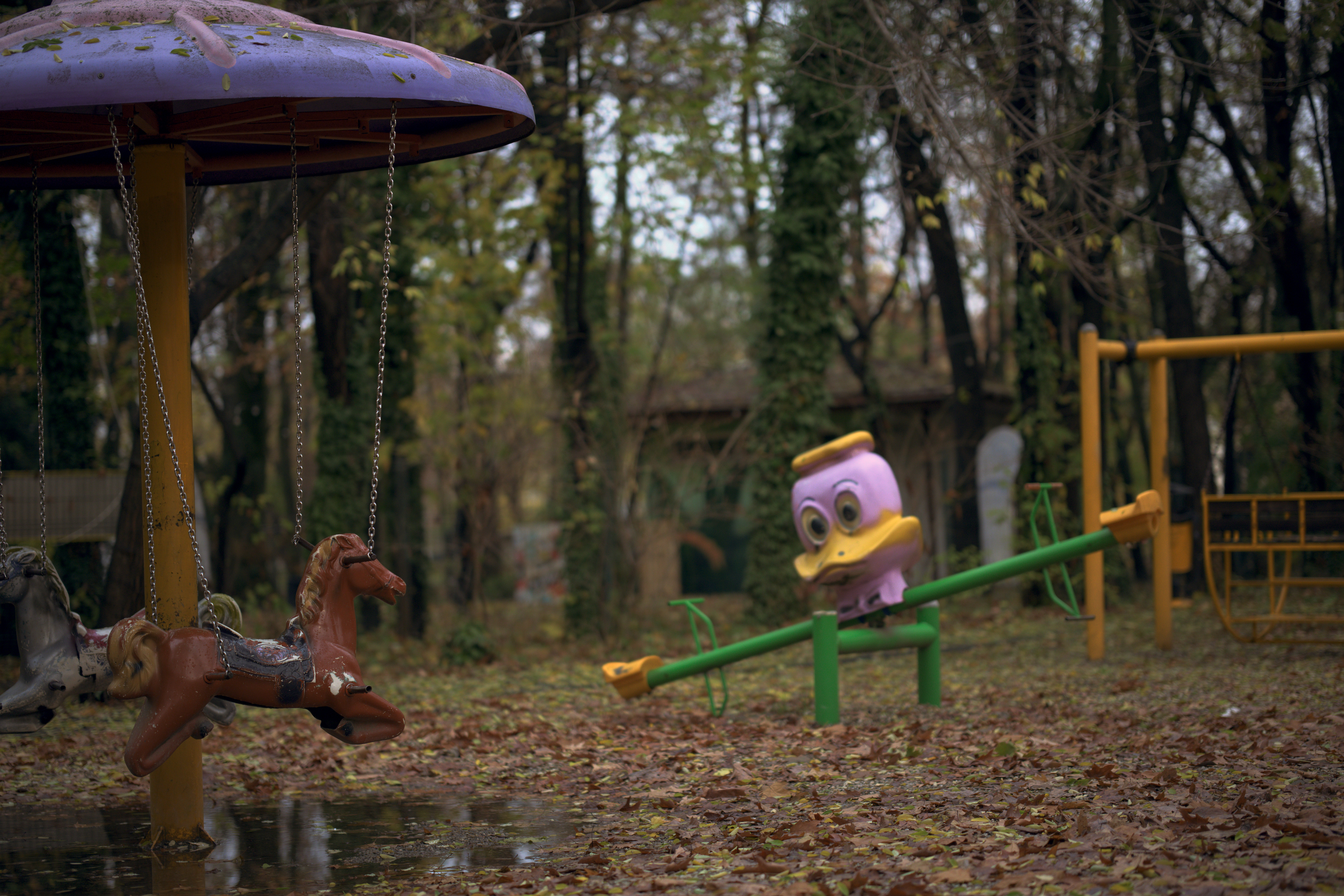
I really like this picture, mostly because while it was actually taken on a perfectly normal wet Autumn afternoon, it has a sense of desolation that feels quite post-apocalyptic. So in each case, I added a little bit of context to my generative AI as well - I wrote my tool so I can add a short “author’s statement” to the prompt it feeds to the language model, to help the AI choose an appropriate mode or theme for its titles and captions. In every case, that statement was:
Photographs taken after the AI Singularity caused an apocalypse which wiped out all human life on Earth.
OK, so that’s the background. How did my AI Captioning go so far?
Attempt 1: BLIP-2⌗
| Asked for… | …the AI generated |
|---|---|
| Image Title | Abandoned Playground |
| Image Caption | A flooded playground with a puddle |
I mean, you can’t say it’s wrong, right?
For this round of efforts, I used a model called BLIP-2. It had the big advantage of being pretty light-weight, light enough that I could run it locally on my own computer with a decent but not spectacular graphics card (an Nvidia RTX3060 with 12gb VRAM). In terms of raw “can I make this work?”, this was a clear success. But the output was… Lacking. In my experiments, I could get BLIP-2 to produce really good ‘factual’ output - I mean, it’s dead right about the puddle, after all - to an extent that would have been amazing only a few years ago, but asking it for any creativity was too much. On raw image-to-text type tasks it’s great, but the language generation skills were lacking for my purposes.
So I tried something else…
Attempt 2: DIY multimodal with RAM+ and GPT-2⌗
Before I reveal the… “special” output of this approach, I should explain what I was trying to do. Obviously, what I needed here was a multimodal AI, one that could work in both the image domain, and the language domain. But most of those models are huge, and won’t run on my local hardware - and at this point I hadn’t discovered Modal. So I thought, what if I take two models which I can run on my machine, and try to Frankenstein a multimodal AI out of it myself?
At this point I’d been using the Recognise Anything, aka RAM, model for a while to very successfully extract tags from images. This model is great - it does exactly what it says on the tin, give it an image and it will recognise what’s in the image, and turn it into a list of tags. So given the images in this gallery, it will come up with a list of tags looking something like this:
keywords = [
"carousel",
"toy",
"playground",
...
So, I figured, what would happen if I took the list of keywords from RAM, and then fed it into a Large Language Model with a prompt along the lines of “a photograph contains the following elements [carousel, toy, playground…], write a description”.
What would happen indeed? This is what happened…
| Asked for… | …the AI generated |
|---|---|
| Image Title | A Flooded Playground |
| Image Caption | I would describe it as a flooded playground. I would say that it is an artificial world. It is not a real world, but a simulation of what it would be like to live in a world where there is no water and no animals, and there are no humans. The only thing that is happening is that the world is becoming more and more artificial. This is what we are seeing now. We are witnessing the beginning of an age of artificial intelligence, where we will be able to do things that we have never done before, such as create new things, create things we can’t do before. And I think that this is going to change the way we think about the future of humanity, because it will change how we see ourselves and our future. So I don’t think we need to worry too much about it. But I do think it’s important to keep in mind that there will always be people out there who are not interested in this kind of thing. They are interested only in what they can do with their time and their money. That’s why I am so concerned about this. If you look at the history of technology, there has been a great deal of progress in the past few decades. In the last few years, the number of people who have access to computers has increased by a factor of 10,000 or more. Nowadays, people are using computers for a lot of different things. For example, you can use a computer to read a book. You can write a letter to a friend, or to your boss. These are all very different kinds of things and they all have their advantages and disadvantages. However, if you want to create something that will make people happy, then you have to make sure that you are doing it for the benefit of everyone, not just the privileged few who can afford to pay for it, so that they will have a better chance of getting a good job and living a normal life. People who do not have the money to buy a car or a house, they have no choice but to spend it on things they cannot afford, like food, clothing and so on. Therefore, we must be careful not to over-promise and under-deliver on the promises we make to the people that are making them happy. As a result of this, when we talk about AI, it seems to me that people will say, “Well, that’s not what I’m talking about.” They will not be happy with the results of their efforts. What they want is for us to think of them as people, rather than as machines that can be used to solve problems that humans cannot solve. When I say “people,” I mean people like you and me, who live and work in different parts of our world and have different needs and needs. Our needs are different from those of any other human being, whether we like it or not. All of us have our own needs, our needs as well as ours as human beings. My point is this: if we want people to feel good about themselves and feel happy about their lives, what is the best way to achieve that? It’s a question that I have been asked many times before: “How do you feel about your life?” And the answer to that question is very simple: it depends on how much you care about yourself and what you do for your family, your friends and your community. How much does it matter to you whether you’re happy or unhappy with yourself or with your world? I believe that what matters most to us is our sense of self-worth and how well we live our lives. A person who is happy and well-adjusted is one who has a sense that he or she is doing well and that his or her life is better than that of other people’s lives because they are living their life in harmony with each other and with nature, with all of nature’s laws and all the laws of physics and chemistry and everything else that comes with being human, is someone who cares about himself and his family more than others do. He cares more about his own happiness than the lives of others and he cares less about others’ lives than he does for himself or for those around him. To me this means that a person is more or less happy if he is living his life according to what he believes is best for him and for his community, as opposed to being happy when he doesn’t feel like doing so. On the other hand, an individual who does not feel well or happy is less likely to |
Oh my!
Well, I can’t complain about it not being creative…
Actually, I was pretty impressed with this. Given the incredibly simplistic approach, it’s actually done a surprisingly good job - if you overlook the fact that the LLM ran off into the weeds pretty quickly, it did at least work out the very basics of the image it was writing about. But a load of keywords clearly don’t give enough context, so instead it obsesses more about the ‘artists statement’ about the apocalypse than the image itself.
But, pretty good, and pretty good for such an ancient LLM. Which LLM? Venerable GPT-2, from the olden-days when OpenAI was actually pretending to be Open.
I figured this would be the best I could do with the hardware I had, and decided this was probably a fun experiment but wasn’t really going to get anywhere - until I discovered Modal.com.
Attempt 3: A genuine, up-to-date multimodal model⌗
What’s Modal? It’s a cloud service provider that essentially rents out server and GPU time, much as any cloud infrastructure provider, but bills on a ‘serverless’ basis - i.e. you only pay for the actual CPU (and GPU) cycles you use, not for the number of hours you need a server. This is a game-changer in terms of the costs of just playing around with large models, and I wrote a lot more, including a brief “how-to”, in an earlier article
And once I discovered Modal, suddenly I could run inference on models way beyond the capabilities of my hardware, at reasonable cost. So I started looking for true multimodal models that weren’t locked behind a paywall, and came upon this paper introducing a new model called Emu2. And, I have to say, it’s amazing…
| Asked for… | …the AI generated |
|---|---|
| Image Title | Forgotten Playground: After The Apocalypse |
| Image Caption | In the aftermath of the ai singularity that wiped out all human life on earth, the children’s playgrounds were left abandoned and overgrown. the once vibrant and lively swings, slides, and merry-go-rounds now stand silent and motionless, a haunting reminder of a time when the park was filled with the laughter and joy of children at play. In the distance, a duck-shaped teeter-totter sways gently in the breeze, seemingly mocking the absence of the children it was meant to entertain. nearby, a horse-shaped merry-go-round spins aimlessly, devoid of the young riders that once filled its seats. the swings, too, sway empty, their chains creaking eerily in the wind. The park has become a haunting reminder of the fragility of life and the fleeting nature of human existence. the playground, once a symbol of innocence and joy, is now a somber reminder of the tragedy that befell the world. |
This is genuinely top-notch. If I wasn’t so lazy and uncreative, it’s what I would have written myself… I’m not sure what else there is to say, other than, OK, what’s next?
Well, to be honest, I’m pretty happy with that. But one set of images is not exactly a comprehensive study; maybe after a few more I’ll see more problems with it. But for now, I’m going to carry on playing with adjusting the prompts I give Emu2, to see what this is really capable of. And then the real next-step will be moving on from simple inference using pre-trained models, to actually fine-tuning and training a model myself.
These are interesting times indeed. Clearly, generative AI is capable of producing an awful lot of, well, crap - but equally clearly, it has huge potential for useful applications as well. Captioning my amateur photography efforts may not be the most life-changing, but it’s proving to be a fun way to explore some of those possibilities.
The complete gallery⌗
The full Emu2 generated gallery titles and captions are below. For comparison, the complete gallery with the BLIP-2 generated captions is here, and similarly the insane ramblings of the RAM+GPT2 Frankenstein are here.
“Forgotten Playground: After The Apocalypse”⌗
in the distance, a duck-shaped teeter-totter sways gently in the breeze, seemingly mocking the absence of the children it was meant to entertain. nearby, a horse-shaped merry-go-round spins aimlessly, devoid of the young riders that once filled its seats. the swings, too, sway empty, their chains creaking eerily in the wind.
the park has become a haunting reminder of the fragility of life and the fleeting nature of human existence. the playground, once a symbol of innocence and joy, is now a somber reminder of the tragedy that befell the world.
“The Apocalypse Playground”⌗
“The Last Merry-Go-Round”⌗

“Graffiti In A Post-Apocalyptic World”⌗
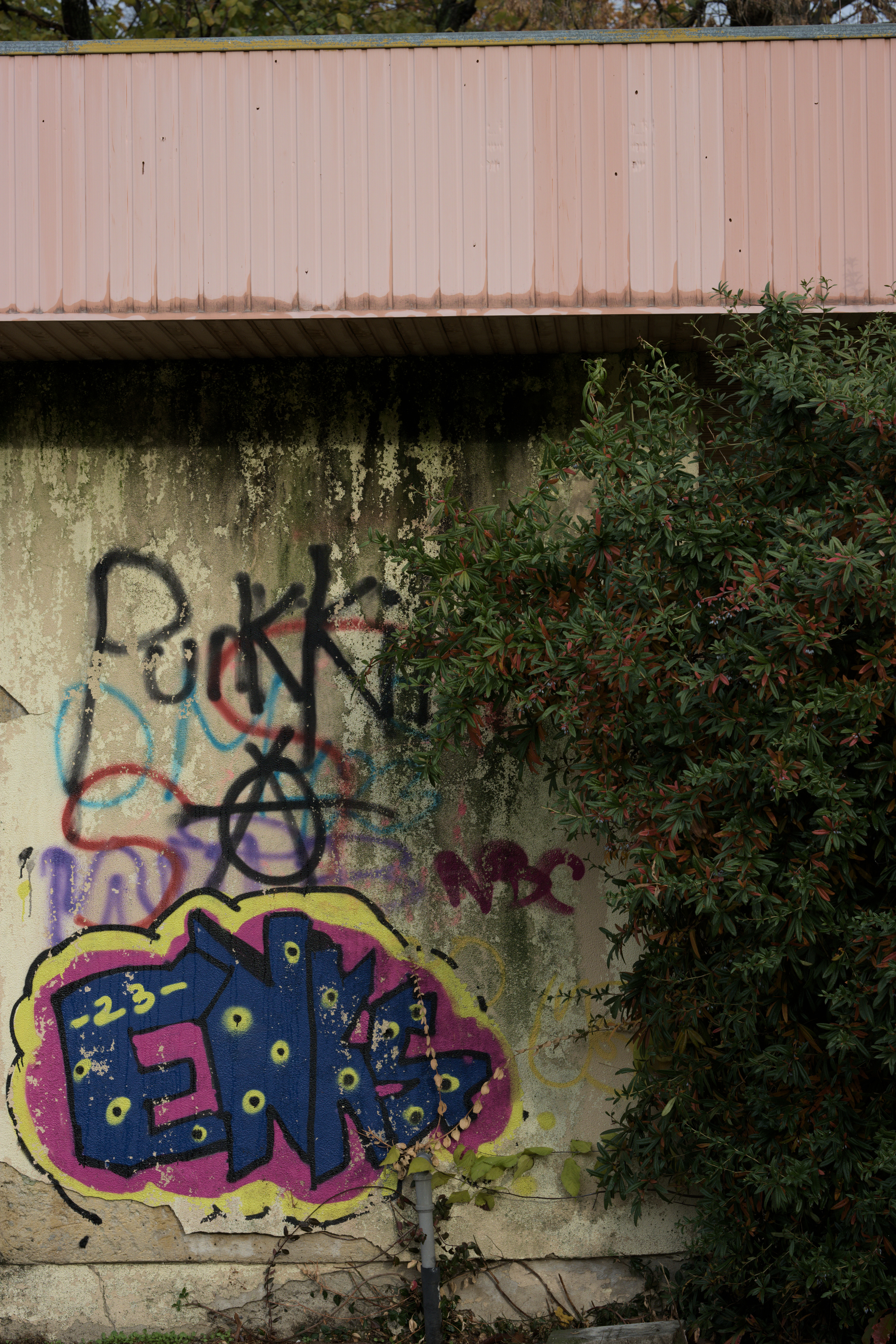
“Graffiti In A Post-Apocalyptic World”⌗

“The Remnants Of Humanity: After The Ai Singularity Apocalypse”⌗
