Fixing Kubernetes TLS Errors
If you run Kubernetes, you may well get used to logfiles full of impenetrable nonsense being churned out on a continuous basis… To say it can be quite “verbose” is an understatement.
You may also be tempted to silence or ignore some of them in whatever tool you use to manage your logging - after all, everything seems to be working fine.
That’s where I’ve been with the “TLS handshake” errors that have been spamming my log server for the last three months. But as my mouse was hovering over the ‘filter’ button, my better side took over and I figured I should do something about it.
As luck would have it, it was relatively easy to fix some of them. But it did take a few Google searches to narrow it down - so I present it here for your benefit.
The Symptom⌗
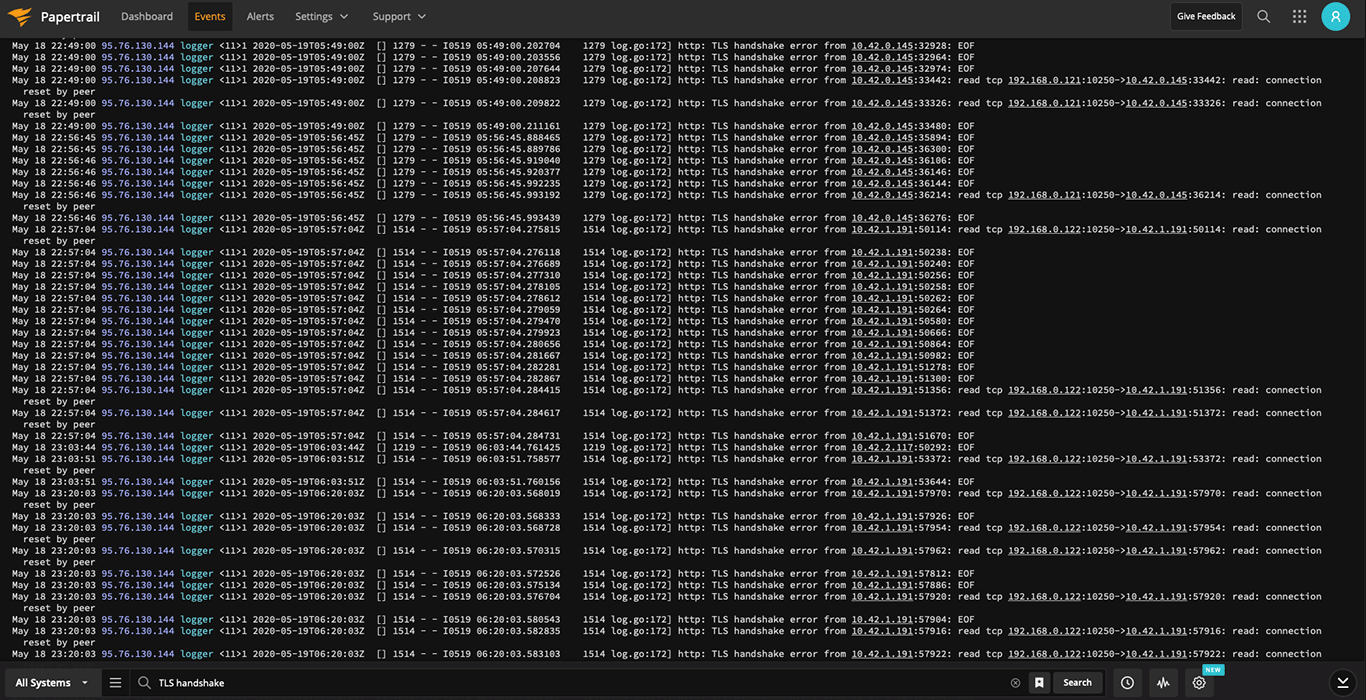
You have logfiles full of messages like this:
May 19 10:51:33 95.76.130.144 logger <11>1 2020-05-19T07:51:33Z [] 1353 - - I0519 07:51:33.036900 1353 log.go:172] http: TLS handshake error from 10.42.2.197:35218: EOF
May 19 10:51:33 95.76.130.144 logger <11>1 2020-05-19T07:51:33Z [] 1353 - - I0519 07:51:33.037838 1353 log.go:172] http: TLS handshake error from 10.42.2.197:35472: EOF
May 19 10:51:33 95.76.130.144 logger <11>1 2020-05-19T07:51:33Z [] 1353 - - I0519 07:51:33.065022 1353 log.go:172] http: TLS handshake error from 10.42.2.197:35670: EOF
May 19 10:51:33 95.76.130.144 logger <11>1 2020-05-19T07:51:33Z [] 1353 - - I0519 07:51:33.070311 1353 log.go:172] http: TLS handshake error from 10.42.2.197:35730: EOF
But otherwise, everything seems fine.
The Cause⌗
Well, a possible cause, anyway - and the cause in my case.
You may have a Max Transmission Unit mismatch between the MTU of the physical machine your Kubernetes workers are running on, and the MTU of the virtual container network.
Try logging in to one of your kubernetes servers, and inspecting the MTU of the Ethernet interface:
[Sasha:~] timwa% ssh -lrancher node2.k8s.int.snowgoons.ro
[rancher@node2 ~]$ ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:1F:16:F6:F0:42
inet addr:192.168.0.122 Bcast:192.168.0.255 Mask:255.255.255.0
inet6 addr: fe80::21f:16ff:fef6:f042/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:110115 errors:0 dropped:9 overruns:0 frame:0
TX packets:76590 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:77558243 (73.9 MiB) TX bytes:12241723 (11.6 MiB)
Interrupt:16
Here we can see the MTU of the physical interface is 1500.
Now let’s check the MTU of the virtual interface of one of the pods. I’ve just picked a random one that I know is running:
[Sasha:~] timwa% kubectl -n dmz exec snowgoons-httpd-576fb64dc7-bh2qb -- ifconfig eth0
eth0 Link encap:Ethernet HWaddr B2:5D:D0:D5:67:CC
inet addr:10.42.2.207 Bcast:0.0.0.0 Mask:255.255.255.255
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:33 errors:0 dropped:0 overruns:0 frame:0
TX packets:17 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:3983 (3.8 KiB) TX bytes:31533 (30.7 KiB)
The problem may not be obvious - but it’s there. The MTU of the virtual interface is the same as the MTU of the physical interface. The problem is this: the virtual interfaces use vxlan (Virtual Xtensible LAN) to manage the virtual overlay networking between pods - which adds a few bytes to every packet which things like virtual LAN IDs. So the actual max transmission unit is less than 1500.
Your MTU on the containers should be (real MTU - 50), to allow for the vxlan overhead. In my case, that means they ought to be 1450, not 1500.
The Solution⌗
The exact solution is going to depend on the virtual networking provider that you use on your Kubernetes installation (Calico, Flannel, whatever.) In my case, Rancher deployments by default use the Canal Container Networking Interface provider.
To change the MTU, I need to edit the canal-config configmap in the kube-system
namespace:
kubectl -n kube-system edit configmap canal-config
And I need to add an entry "mtu": 1450, under the "type": "calico" line:
apiVersion: v1
data:
canal_iface: ""
cni_network_config: |-
{
"name": "k8s-pod-network",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "calico",
"mtu": 1450,
"log_level": "WARNING",
"datastore_type": "kubernetes",
"nodename": "__KUBERNETES_NODE_NAME__",
...
Save the config, and hey-presto - no more TLS error spam in my logs.
Well, not quite hey-presto; the new config will only take effect for newly created pods. So the final step was to restart all my servers.
I hope that helps anyone having similar problems!
Update⌗
And, in fact, not exactly “no more” TLS error spam in my logs. A significant
reduction, but far from eliminated. So it looks like that was the cause of
some, but not all, of my Kubernetes networking woes:

The search for other problems goes on; if I find anything interesting, I’ll write :-).