Tell me about your CMS
Contents
What’s the story?⌗
I know what you’re thinking; this site must be built with a terribly advanced CMS. Well, yes, in a way it is - advanced in the sense of being incredibly simple. And I am a big fan of simple…
In my day job, I’m lucky enough to architect systems that deal with huge peaks in traffic, with users making real-money transactions - thousands per second - in real-time; that means any kind of downtime costs serious money. I’m also unlucky enough that it’s an industry that is under constant, relentless attack from hackers and attempted Denial-of-Service extortions; you never forget the first time your boss approaches you to tell you he’s had an anonymous demand to wire $50,000 to a selection of Western Union branches in Estonia, and mine was almost 20 years ago - since then (a mere 1Gb/s attack - a lot of bandwidth in those days) “can cope with anything a bad guy throws at us” has been an explicit requirement in everything I design.
In that world, the traditional CMS tends to be a liability more than an asset, and while this website measures page views per week, not per second, I figured I might as well use the same kind of design principles I’d follow in my day job to build the architecture behind it. And since I was also inspired by this excellent article on ArsTechnica, I thought I’d describe some of what I’ve done here.
What do you mean by a traditional CMS?⌗
Before I explain what’s different about this site, it’s worth explaining what I mean by ’traditional CMS’. To name names, I’m thinking of applications like Wordpress, Drupal or Joomla - all very good choices in their own way. I’m not setting out to trash-talk any of them here, I host a friend’s blog here using Wordpress, and one of my other websites is still using Joomla, which was also the basis for the previous version of this site.
These applications all tend to look somewhat similar:
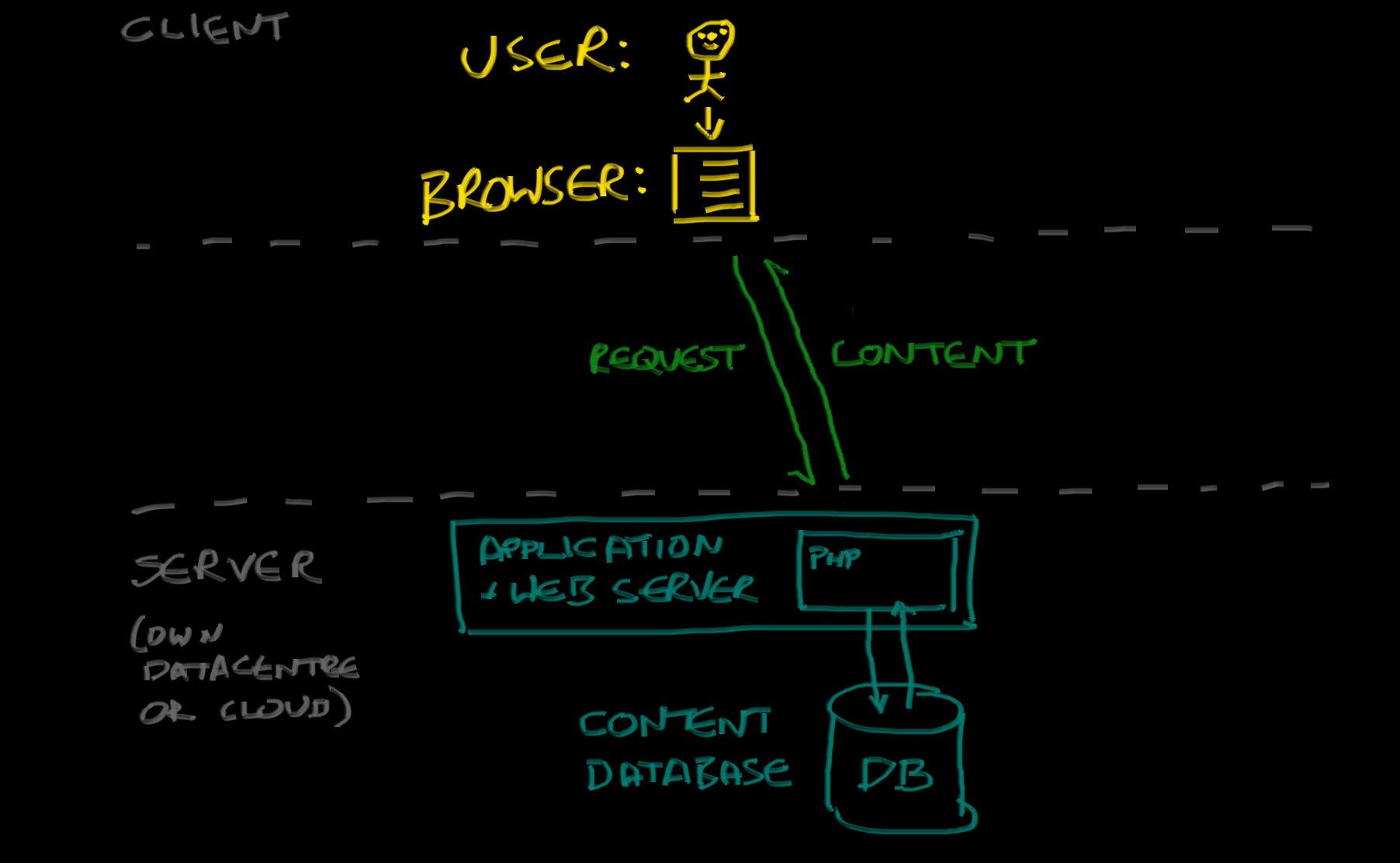
Typically, you will have an application server tier that responds to requests for pages to be rendered from the client. When a client requests a page, the application will check if it already has an up-to-date copy of the page in its page cache, and if so it will simply return it. If not, it will go to the database, pull out the information it needs (page content, keywords, which template should be used to render the page - that sort of thing), run it through a rendering engine, and then return the page at the same time as updating its own local cache.
There is much that is good about this model, from a site publisher requirements perspective. Because all the content to be rendered sits in a database, it’s easy to produce truly dynamic sites - you can add the content in the ‘back office’ of the CMS, and as soon as you hit “publish” the content is available; all the menus that point to the content will be updated, the Search function will know about it, as soon as a user comes and asks for your hot new blog post the content is pulled out of the database and rendered on-demand. It’s great, and super easy to use.
There are, however, a few downsides to this model:
- Your web application server needs to run some kind of scripting language. Typically, it’s often as not PHP, but anyway it needs to be ‘smart’. That means more compute resources required than a dumb webserver.
- You need to maintain a database server. These days that’s not a huge task with cloud-based services like Amazon RDS, but still, it’s work.
- Security. Your application server by definition needs to be able to execute code, not just dumbly serve files - and as soon as you can execute code, you are open to security problems. Even if you trust 100% the security of the application you’ve chosen (e.g. Wordpress), you also need to trust all the themes, plugins and other toys you found on the Internet to make your site look pretty. Miss installing one critical update for a few days, and at best your website became a part of the many bot-armies spamming the world with “I hacked your camera, send bitcoin” emails, at worst your database contents have been downloaded and are for sale on the dark-web. Oh, and did I mention just by having a database, you’ve hugely increased your attack surface for the bad guys to exploit SQL-Injection and other vulnerabilities?
- Scalability. If the security problems weren’t bad enough, this is the one that kills you when you’re being Denial-of-Service attacked, or just when your site gets popular. The traditional model simply doesn’t scale up to huge volumes.
Doesn’t scale? Nonsense!⌗
Sure, you can throw servers at a site like this - keep adding application servers to handle the load. That works up to a point, and you can run a pretty big site this way - but when you’re talking really big scale, you start running into problems. Eventually, the database becomes your bottleneck - and scaling up databases is no fun at all. Born out of bitter experience (in a past life I ran the IT for a major satellite sports broadcaster, and we had to deal with literally hundreds of millions of page impressions per hour on match days - all of which had to contain up-to-date information), I am a firm believer in the theory that the best way to scale a database is to not have a database at all.
SO what’s the typical solution?
Cacheing. It’s always cacheing.⌗
…And there’s nothing wrong with that. When your site gets big, either because it’s wildly successful (go you!), or because some mofo is hitting you with a Denial of Service attack, eventually you will solve the problem with cacheing. It might be local caches, in your infrastructure, or some kind of magic database cache sitting between the application tier and the database, but you’ll have cacheing of one kind or another.
The simplest to explain, simplest to implement, and often most effective solution is to put a cache in front of your application servers - often one hosted in the cloud, otherwise known as a Content Delivery Network:
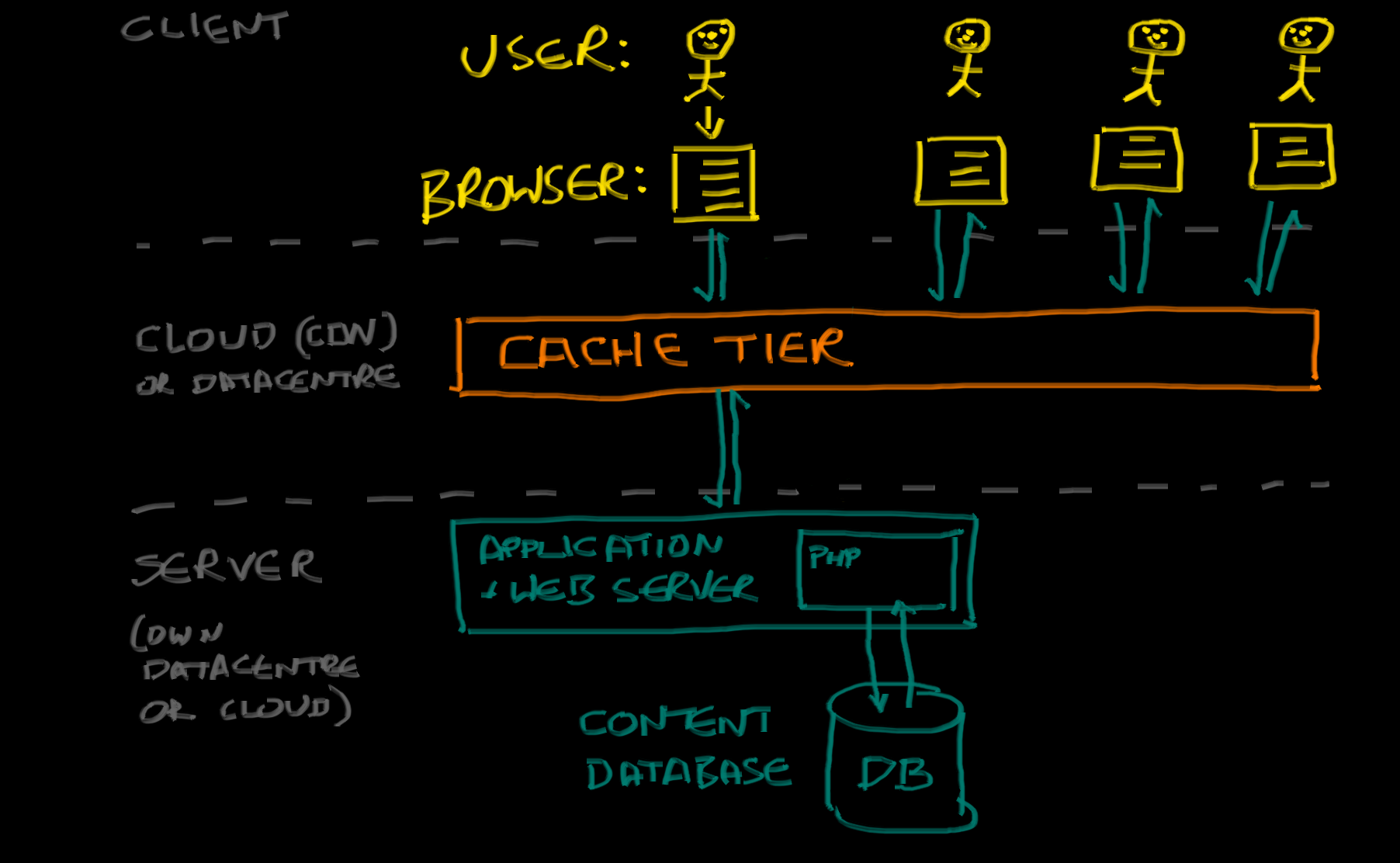
By putting a CDN in front of your site, you can achieve a few things; firstly, you put your content ‘closer to’ the end users, so it loads faster and uses less of the bandwidth in your datacentre (known as the ‘origin’). This tends to be the most advertised selling point of a CDN, but it’s not the big win. The “big win” comes from the fact that - when properly deployed - no matter how many users are asking for a particular page, the CDN only needs to ask your origin servers for the page once1.
PRO-TIP: Find the configuration settings in your CDN or cache provider for the “Stale while revalidate” (serve old content until your server responds with the latest version) and “Background (or asynchronous) refresh”, to provide an effective insulation against Denial of Service attacks, and to give the impression your site is working just fine even when behind the scenes everything is on fire.
OK, so if there’s a solution to the problem… What’s the problem?⌗
If the solution is always cacheing, the problem with that is always cache age.
You’ve put a lot of effort into building a super-dynamic site, with a super-dynamic Content Management System, so that the instant someone clicks on Publish the content is visible on your site… And now you have to wait 5 minutes for the cache to expire before any actual users see the content. Worse still, one of resources has updated in the cache, but some of the ones it depends on are still on the old version, so you’ve got broken links or images on the pages until everything expires and it just looks a mess and oh… AAARGH!
These are all problems that are solvable. You can spend a lifetime tuning your cacheing times, fiddling with etags, using an API to automatically expunge content from the cache when somebody changes something in the back end…
They’re solvable but it’s complicated. And I think I said up there - I really really like simple solutions.
The Critical Realisation⌗
All of this story (and bitter experience) has led me to a simple realisation:
At some point, you are going to end up having a cache in your infrastructure.
As soon as you have a cache in your infrastructure, you have moved into a world where you’re having to manage delivering static assets (from the cache).
So why not just make your life easier, and assume you’re delivering static assets anyway. Embrace it.
And so, enter stage-left, with a flourish:
Static Site Generation⌗
I like to think of a Static Site Generator as basically doing everything our traditional CMS does - just in a slightly different order.
Consider this flow diagram showing a typical CMS solution:
In this simplified example, our user creates a new page, “About”, and the CMS records all the details in the database. Then, when the user asks to see the page, the CMS retrieves the details, and renders it for the user.
The key issue is that last bit. Now when another user asks for a page, the flow looks like this:
Everything works, it’s all good - but it’s inefficient. Now consider how a Static Site Generator does things:
The key thing to note is this - now the actual request for a page is trivial; it was already rendered, just service it from disk. We turned it into static content - hence Static Site Generator.
Seems obvious. Why do anything else?⌗
Or maybe the better question is, why was it ever done any differently?
Well, I glossed over something important there. The “render any pages that reference it” step in the page generation - that can be a lot of work. In fact, you can basically generalise it to “rebuild the entire site, every time a single item of content changes.” In the olden-days, when both storage (for all the rendered content) and CPU time (to render the whole site every time a page changed) were expensive, this wasn’t practical.
But now storage is cheap. And CPU is ridiculously cheap, and on the whole we have more than we could ever need. My mobile phone is literally more powerful on every meaningful metric than the Sun Enterprise V880 that cost $40,000 when it was powering one of my (work!) websites 20 years ago.
Moore’s Law in effect means that today, it is entirely practical to rebuild my entire website every time a piece of content changes. And from an architecture perspective, that’s great - because now we can optimise for the right thing: page views. It also means that, because the whole things gets rebuilt every time anyway, all my cache-coherency problems pretty much go away and I can just invalidate the whole CDN cache when anything changes - so I simplified my whole CDN model.
To summarise:
| Type of CMS | Updating pages | Viewing pages | Optimal for |
|---|---|---|---|
| Classic CMS | Quick | CPU intensive | Sites with more editors than readers |
| Static Site Generator | CPU intensive | Quick | Sites with more readers than editors |
Now, I will accept the criticism that for this website, that tends to suggest a classic CMS is more than adequate. But you never know, maybe one day it’ll be popular…
I’m convinced! Tell me what you use⌗
So, after all that lengthy justification, what Static Site Generator did I choose to build this site? Well, I tried a few, and without very scientific analysis I settled on Hugo.
Hugo is a Static Site Generator written in Go. You can think of it as like
a compiler for websites - take a directory full of content files, run the command
hugo, and it will compile it all together into a directory with all your
rendered HTML content.
To do this, it basically takes the content you provide as regular text files
in a directory structure, and combines it with presentation logic that is
also provided in text files. Typically, you’re going to start with a theme,
so when you’re starting from scratch it really is as simple as downloading the
theme, and starting to edit your content. Then either type hugo server to
preview it on a local server, or simply hugo to compile it all into a
static directory of HTML (and all the static assets it relies on.)
PRO-TIP: If you’re just starting out with Hugo, be wary of many of the themes you will find. A theme basically has total freedom to do stuff the way the theme author wanted it done, and when you’re searching the Internet for Hugo examples, you may find stuff that ought to work fine but doesn’t on your site. If it’s your first time, you won’t know if this is:
- Because Hugo sucks (clue, it doesn’t.)
- Because you suck (I thought I did.)
- Because the theme you installed sucks and broke basic things.
I strongly suggest get started with a super simple theme like BeautifulHugo to learn the ropes, and then start looking at more adventurous options.
What else is cool about Hugo?⌗
Well, the thing I think I like most about Hugo is this, my CMS UI:
In case you’re thinking “that looks a lot like a programmer’s IDE”, that’s because that’s exactly what it is - CLion2 from JetBrains. You could of course use any old tool you prefer, because your content database is just a bunch of flat files. Of course this isn’t for everyone - and more traditional CMS interfaces for Static Site Generators do exist - but for me, I love it. There is no way I would have written this long blog post into a web based UI - but writing it into a text file, on disk, version controlled with Git the same as the rest of my code… It just seems so natural.
Oh, and one other thing you may have noticed from that image: Hugo can use
a variety of text formats, but the one it’s most at home with is
Markdown. It’s much more lightweight and
simple than HTML, and does a much better job of allowing you to write content
and forget about styling/presentation. And bonus points, if you’re a software
developer of any kind, you’re probably already familiar with Markdown, because
you’re using it to write the README.md file at the top of every project,
or to record your Architectural Decision Records (ADRs) in source control,
or for any one of a hundred other reasons…
I mean, I was sold at “not HTML”, but that’s a load of other great reasons to use it right there.
Wrapping Up⌗
OK, so I’m pretty much out of steam right now. Hope you might have found a nugget of interest or truth in here - I enjoyed writing it even if nobody else enjoyed reading it (and if you guessed I was using it as an excuse to play with the rather brilliant js-sequence-diagrams library by @TheBramp, you’d be right.)
Next time, I’ll write about my build and hosting process - how content gets from Hugo onto my Kubernetes cluster, and from there to you, the viewer. Singular use intended.
Further Reading⌗
- If you want to know how to deploy, here’s how I built the site
- If you’re curious about what hardware I host this on, Read This
-
OK, often more than once depending on the architecture of the CDN - you may get a request from each of their datacentres for example - but the point is it no longer scales up directly with the number of users. ↩︎
-
It’s the IDE with the closest approximation to Emacs keymapping I’ve ever found. I stuck by Emacs almost my whole life, but I have to confess I find the integrations of things like Docker & Kubernetes into an IDE super useful… ↩︎